Real estate price prediction in the Czech Republic based on real data and machine learning.
Real Estate Predict
Real Estate Predict is a data-driven project focused on estimating market prices of apartments and family houses in the Czech Republic. The project combines work with predictive models, collection of real market data, and the creation of a simple web application that allows users to estimate the price of a specific property based on provided parameters.
Highlights
Prediction models
Interactive maps
Data export
Case study
Structured overview of the challenge, solution, and results.
Problem
Property prices in the Czech Republic are heavily influenced by location, layout, and other factors, but the average user lacks a simple tool to quickly verify whether the asking price is realistic. Publicly available data is often inconsistent, uncleaned, and there is no transparent way to create a comprehensible price estimate from it. The goal of the project was to create a predictive model that would: - work with real data from the Czech market, - be able to estimate the price of a property based on key inputs, - and be accessible through a simple web interface.
Solution
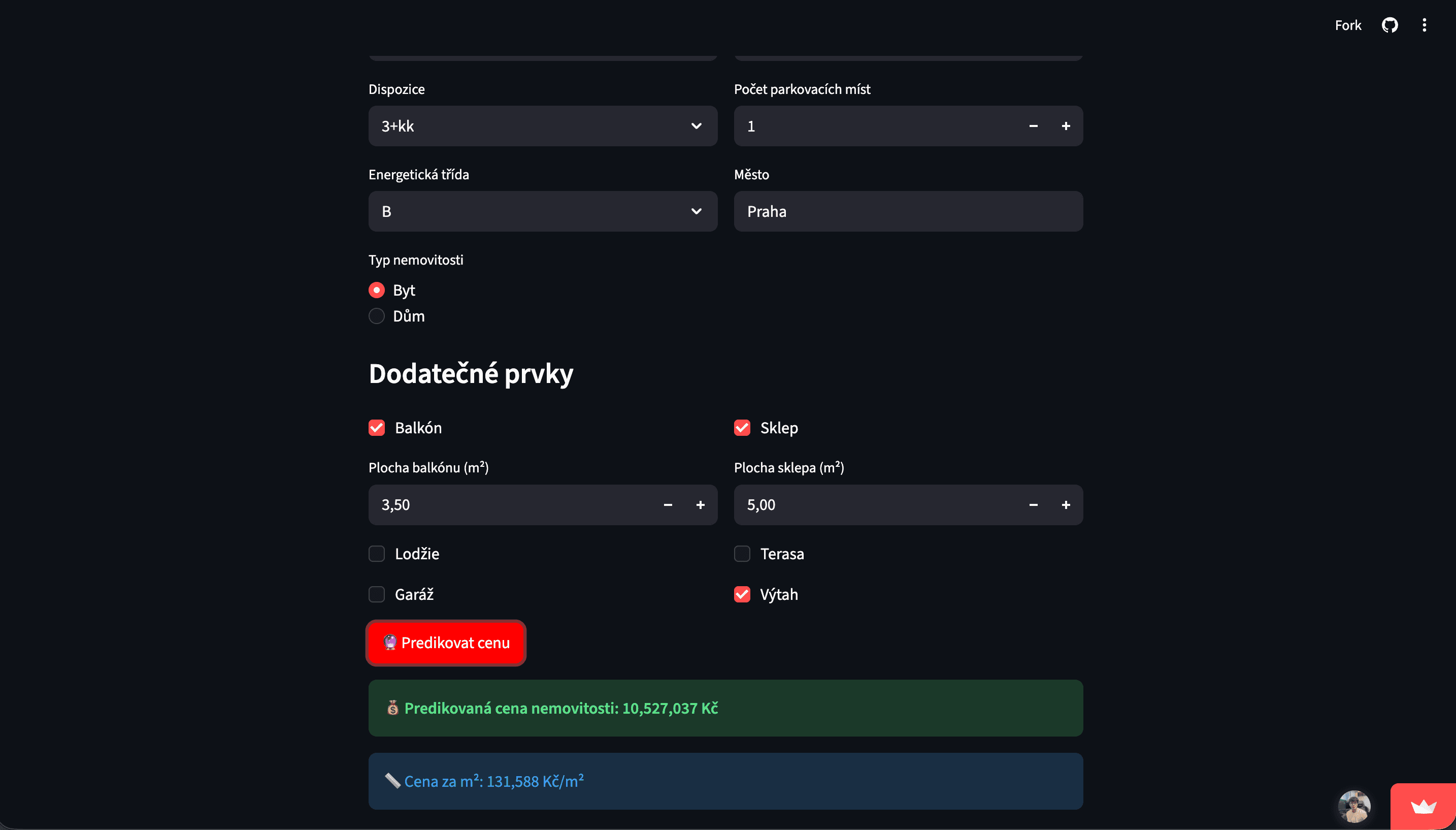
The project began with experimenting with predictive models, specifically Linear Regression and XGBoost, on training data from the Kaggle platform. This phase served to understand the behavior of the models and select an appropriate approach. Subsequently, a custom Python web scraper was created to collect data from the bezrealitky.cz portal. The result was approximately 2,500 listings that underwent a process of cleaning, normalization, and feature engineering. An XGBoost model was trained on this prepared real data, achieving better results than the basic linear approach. To present the results, a simple web application was created in Streamlit, where the user inputs property parameters (location, layout, area, etc.) and receives an estimate of its price. The entire application was then deployed using GitHub Pages and Streamlit Cloud.
Outcome
The result is a functional end-to-end project that: combines the collection of real data, its processing, and machine learning, utilizes a more advanced model (XGBoost) for price prediction, offers a user-friendly interface for practical use, and demonstrates the entire process from data to deployed application. The project serves as an example of the ability to work with data, design predictive solutions, and translate a technical model into a comprehensible product.
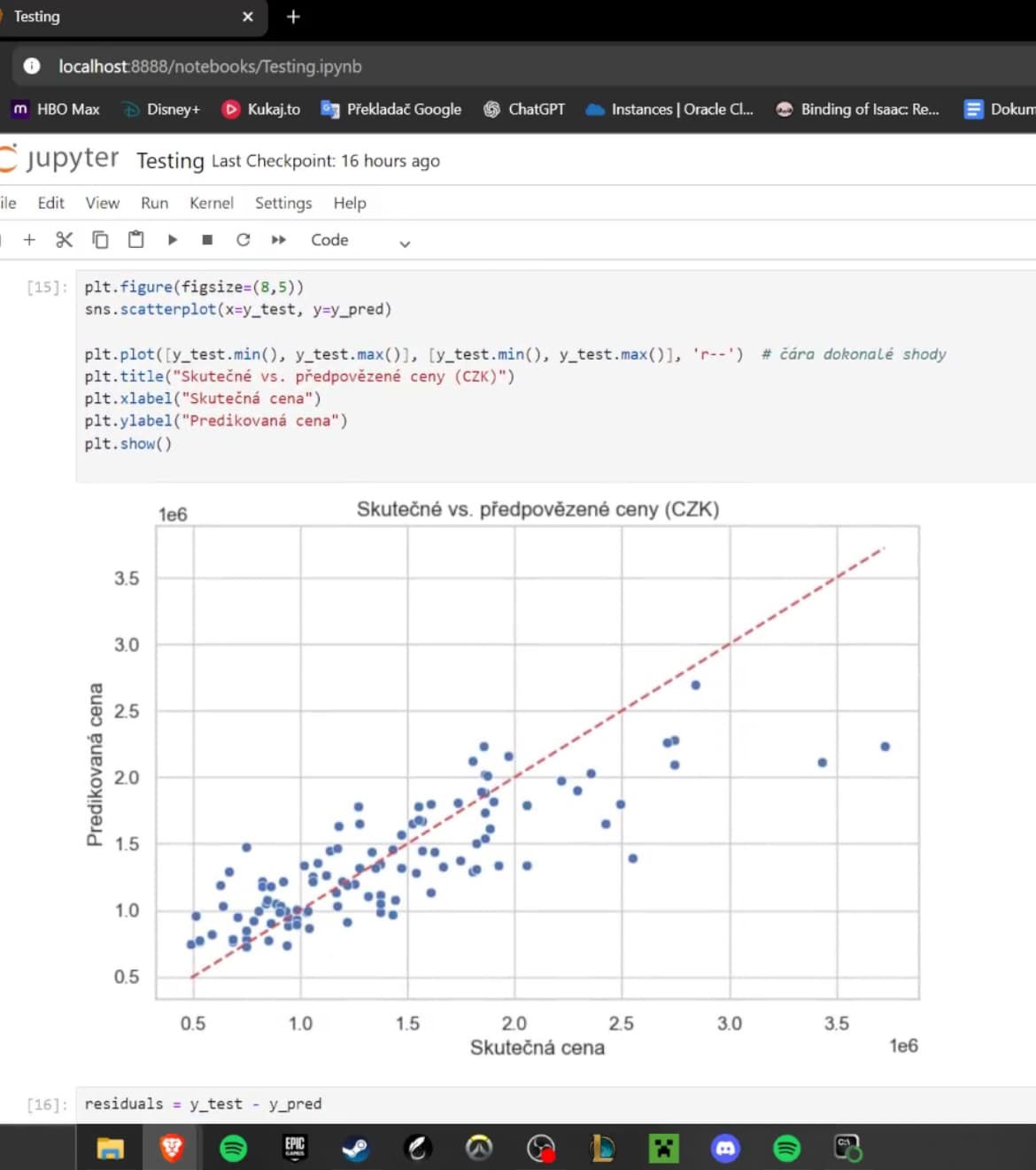
A space for testing, learning, and verifying work with data and models.
Visual
Experimentation and Testing
All experimentation took place in a Jupyter Notebook environment, where I gradually worked with raw data, their analysis, and visualization. This phase served not only to test predictive models but also to understand the data itself and its behavior. Within the notebooks, I learned to work with data analysis, create graphs, perform web scraping, and evaluate model accuracy using metrics such as absolute and relative deviations. Testing allowed me to iteratively improve the approach to data and the final quality of predictions before deploying the final solution.