Predikce cen nemovitostí v ČR založená na reálných datech a strojovém učení.
Real Estate Predict
Real Estate Predict je datově-orientovaný projekt zaměřený na odhad tržních cen bytů a rodinných domů v České republice. Projekt kombinuje práci s prediktivními modely, sběr reálných dat z trhu a tvorbu jednoduché webové aplikace, která umožňuje uživatelům odhadnout cenu konkrétní nemovitosti na základě zadaných parametrů.
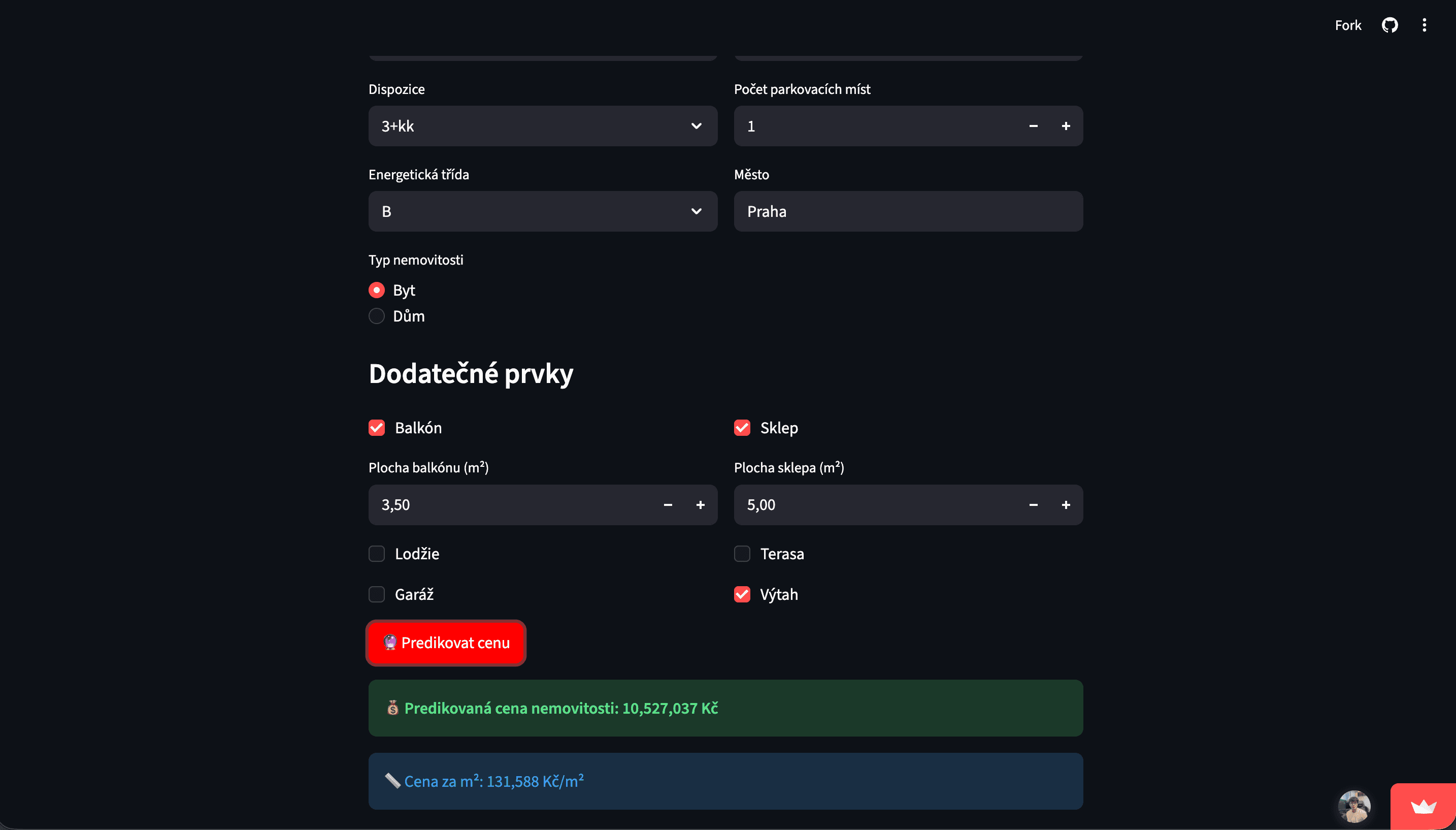
Případová studie
Strukturovaný přehled problému, řešení a výsledků.
Problém
Ceny nemovitostí v ČR jsou silně ovlivněny lokalitou, dispozicí a dalšími faktory, ale běžný uživatel nemá jednoduchý nástroj, jak si rychle ověřit, zda je nabídková cena realistická. Veřejně dostupná data jsou často nejednotná, nevyčištěná a neexistuje transparentní způsob, jak z nich vytvořit srozumitelný odhad ceny. Cílem projektu bylo vytvořit prediktivní model, který by: - pracoval s reálnými daty z českého trhu, - dokázal odhadnout cenu nemovitosti na základě klíčových vstupů, - a byl dostupný skrze jednoduché webové rozhraní.
Řešení
Projekt začal experimentováním s prediktivními modely, konkrétně Linear Regression a XGBoost, na tréninkových datech z platformy Kaggle. Tato fáze sloužila k pochopení chování modelů a výběru vhodného přístupu. Následně byl vytvořen vlastní Python web scraper pro sběr dat z portálu bezrealitky.cz. Výsledkem bylo přibližně 2 500 inzerátů, které prošly procesem čištění, normalizace a feature engineeringu. Na takto připravených reálných datech byl natrénován model XGBoost, který dosahoval lepších výsledků než základní lineární přístup. Pro prezentaci výsledků vznikla jednoduchá webová aplikace ve Streamlit, kde uživatel zadá parametry nemovitosti (lokalita, dispozice, plocha apod.) a získá odhad její ceny. Celá aplikace byla následně nasazena pomocí GitHub Pages a Streamlit Cloud.
Výsledek
Výsledkem je funkční end-to-end projekt, který: - kombinuje sběr reálných dat, jejich zpracování a strojové učení, - využívá pokročilejší model (XGBoost) pro predikci cen, - nabízí uživatelsky jednoduché rozhraní pro praktické využití, - a demonstruje celý proces od dat až po nasazenou aplikaci. - Projekt slouží jako ukázka schopnosti pracovat s daty, navrhnout prediktivní řešení a převést technický model do srozumitelného produktu.
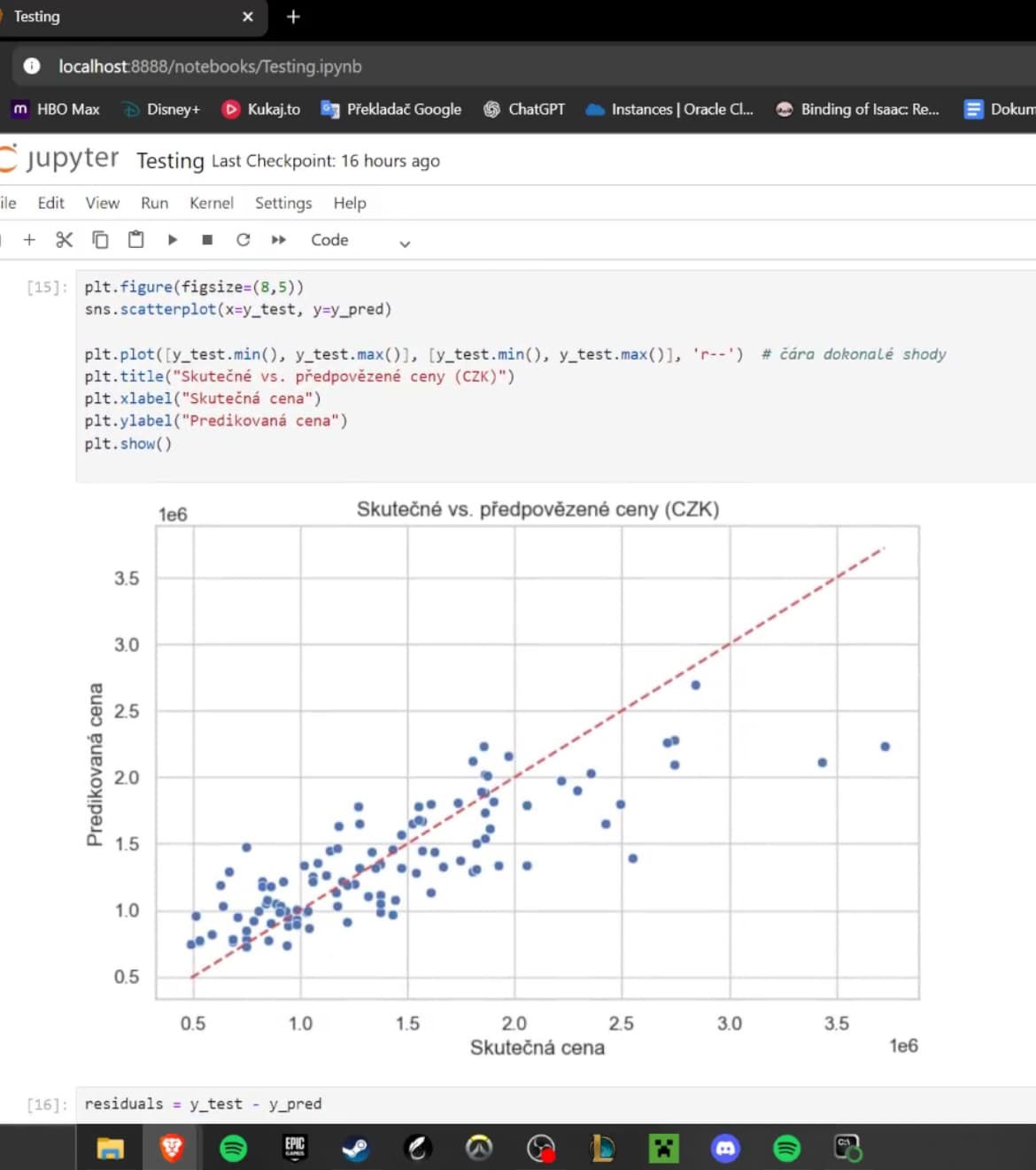
Vizual
Experimentování a testování
Veškeré experimentování probíhalo v prostředí Jupyter Notebook, kde jsem postupně pracoval se surovými daty, jejich analýzou a vizualizací. Tato fáze sloužila nejen k testování prediktivních modelů, ale také k pochopení samotných dat a jejich chování. V rámci notebooků jsem se učil práci s datovou analýzou, tvorbou grafů, web scrapováním a vyhodnocováním přesnosti modelů pomocí metrik, jako jsou absolutní a relativní odchylky. Testování mi umožnilo iterativně zlepšovat přístup k datům i výslednou kvalitu predikcí před nasazením finálního řešení.